


Qu’est-ce qu’une semantic layer ?
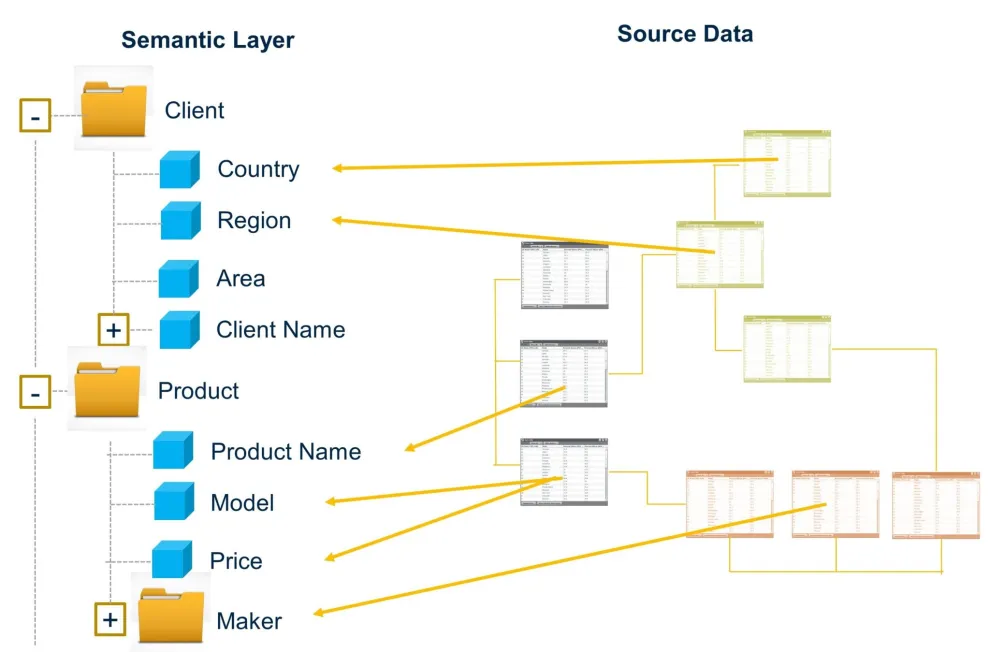
Une semantic layer est une couche d’abstraction présentant des données à des utilisateurs, dans un cadre orienté métier et sous un format facilement compréhensible par des personnes non techniques.
Cette couche est généralement la dernière couche d’un datawarehouse, située au-dessus des données techniques et exposée aux utilisateurs finaux. C’est en quelque sorte une traduction des données techniques produites par les équipes data en des données orientées métier, exploitables par toutes et tous. Ces données sont mises à disposition des utilisateurs finaux via des tables dans une base de données ou une API par exemple.
Quels sont les avantages d’une couche sémantique ?
Cette couche d’abstraction permet d’uniformiser le traitement, le calcul, le format et la dénomination de données utilisées de manière différente par plusieurs métiers. Il est encore courant dans les entreprises que les équipes utilisent des termes différents pour désigner une même information (par exemple “abonné”, “actif”, “utilisateur” pour identifier une entité ayant accès au contenu d’un média).
En mettant à disposition des équipes consommatrices, via un catalogue par exemple, des metrics cadrées, pré-calculées et standardisées, il est alors possible d’assurer la cohérence des valeurs et de lutter contre l’isolement des informations. De plus, cette approche facilite grandement la maintenance puisque si la méthode de calcul change, il suffira alors de mettre à jour la formule à un seul endroit pour que l’intégralité des utilisations soit impactée.
Cette couche sert donc de référentiel gérant à la fois le data modeling, les méthodes de calcul, les règles métier et les accès à la donnée.
L’utilisation d’une semantic layer apporte une couche supplémentaire de sécurité au sein des architectures de données en centralisant l’accès et la gestion des données. En définissant des règles précises d’accès et de visibilité, elle permet un contrôle rigoureux sur qui peut accéder à quelles données, minimisant ainsi les risques de fuites ou d’expositions non autorisées.
Les solutions du marché pour construire des semantic layers : Avantages &, Inconvénients
Il existe beaucoup de solutions proposant de construire des semantic layers sur le marché. Une partie d’entre elles, historiquement les premières, sont directement intégrées à des outils de Business Intelligence (BI) comme Power BI (DMX) ou Metabase. Cela a l’avantage d’assurer une parfaite compatibilité entre la semantic layer et l’outil de visualisation mais restreint l’entreprise à une seule solution et une finalité uniquement analytiques, excluant de nombreux cas d’usage comme de l’embedded analytics ou de l’IA. Il existe également des solutions standalone, comme Cube.js ou AtScale, indépendantes de toute solution de Business intelligence.
Dans cette partie, nous présenterons dans les grandes lignes quelques solutions du marché et analyserons leurs avantages et inconvénients.
DBT Semantic Layer
DBT est un outil open-source de transformation de données très largement utilisé dans le monde de la data. DBT propose, grâce à MetricFlow, une semantic layer appelée dbt Semantic Layer. La solution repose sur la création de modèles SQL pour structurer les données selon des règles métier. Il est possible d’y inclure de la documentation et de définir des tests de validation automatiques.
dbt Semantic Layer s'intègre de manière transparente à plusieurs applications : Tableau, Google Sheet, Steep... Pour les autres, il est possible d’accéder à la donnée via les langages ou outils JDBC, ADBC et GraphQL APIs.
Principal inconvénient de cette solution, elle n’est disponible que dans l‘offre payante dbt Cloud Team ou Enterprise. L’avantage est que si vous utilisez dbt pour vos transformations de données, vous pourrez éviter d’utiliser trop d’outils différents et concentrer toute la modélisation, la transformation et la semantic layer dans un seul emplacement.

Looker
Looker, la plateforme de Business Intelligence développée par Google, propose elle aussi une semantic layer. Cette solution s’appuie sur le langage LookML permettant de décrire des dimensions, des agrégats, des calculs et des relations entre des données stockées dans une base. Ce langage prend en charge toutes les implémentations SQL.
Historiquement restreinte à Looker, la semantic layer est maintenant ouverte à des outils externes tels que Google Spreadsheet, Google Slide, PowerBI ou Tableau. Elle propose également une intégration via Rest API et JDBC. Pour la connexion aux sources, l’interaction avec les données est grandement facilitée si le datawarehouse sous-jacent est BigQuery.
Looker a fait de sa semantic layer un véritable axe stratégique et des innovations devraient voir le jour dans le futur.

Cube.js
Cube.js est une solution open-source standalone permettant de mettre en place une semantic layer pour construire des applications analytics.
Cette solution peut se connecter à n’importe quelle source de données supportant le SQL et mettre à disposition de n’importe quelle application des modèles de données pré-agrégés sous forme de endpoints.
Cube.js propose une offre open-source et une solution cloud permettant d’héberger son instance et d’accéder à une interface web pour modéliser, tester et visualiser ses modèles de données.

Cube.js est une solution que nous utilisons beaucoup chez Modeo. Dans le prochain article de cette série, nous parlerons plus en détails de cet outil incontournable de la Modern Data Stack.

%20(1).webp)