


Les grandes avancées technologiques de ces dernières années ont permis l’apparition d’un nouveau type de Data Platform, les Modern Data Platforms.
Le concept reste le même, créer un outil central de gestion de la donnée au sein d’une entreprise, mais les moyens pour y arriver ont grandement évolué.
Entrons dans le vif du sujet.
Une Modern Data Platform (MDP) est une architecture de traitement de données moderne qui permet de collecter, stocker, transformer et analyser les données de manière efficace et évolutive. Contrairement aux architectures traditionnelles, la MDP utilise des outils cloud-native et des services SaaS pour offrir une meilleure agilité et des performances accrues.
C’est grâce à cette Modern Data Platform que sont développés des cas d’usage data, tels que :
- Dashboard de pilotage (financier, marketing…)
- Segmentation client, optimisation des campagnes marketing
- Prédictions, machine learning…
Quelle est la différence entre la Modern Data Stack et une Modern Data Platform ?
Les termes Data Platform et Data Stack sont parfois utilisés de manière interchangeable et cela peut mener à des confusions. En théorie, une Data Platform est l'ensemble des composants à travers lesquels les données circulent, de leur collecte à leur restitution, tandis qu'une data stack est l'ensemble des outils qui servent ces composants.
Une Modern Data Platform est donc composée des solutions de la Modern Data Stack.
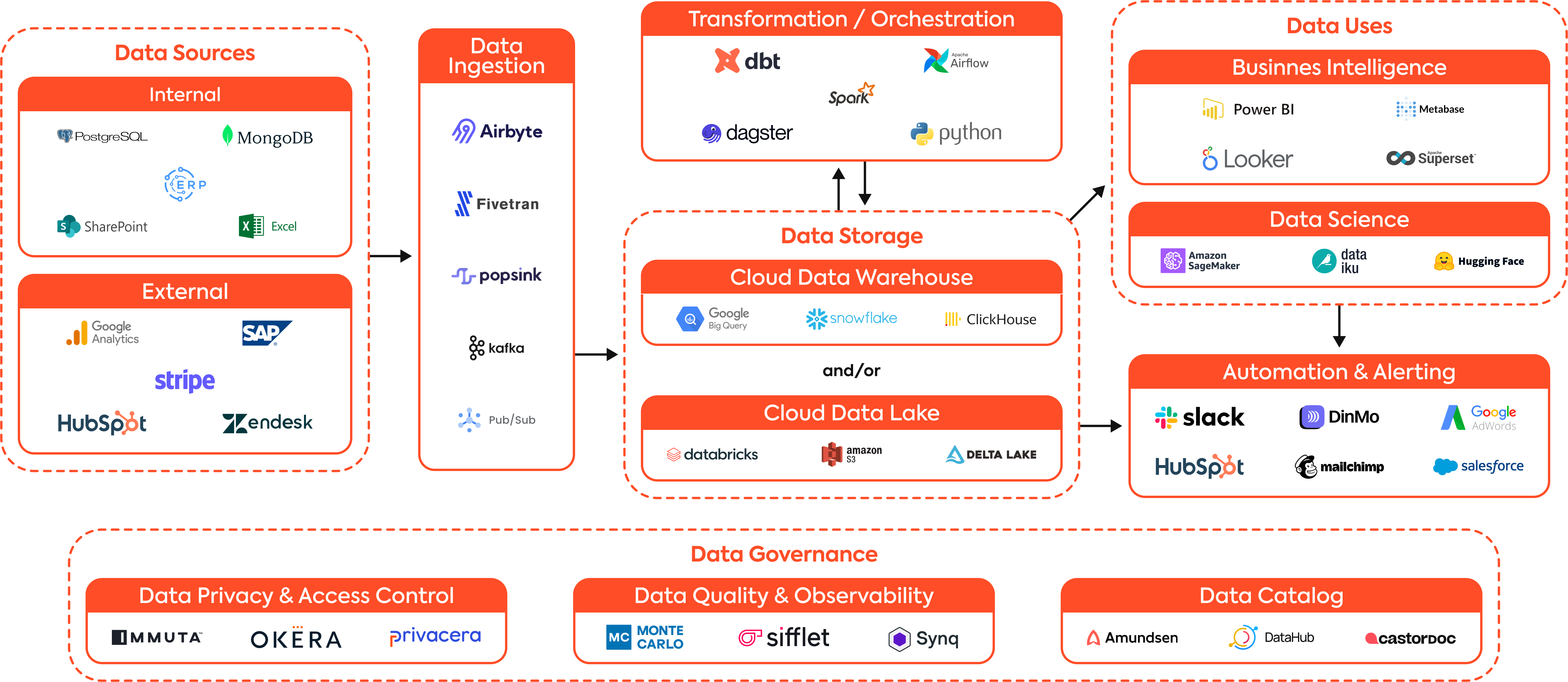
Quels sont les critères à prendre en compte lors de la mise en place d’une MDP ?
• Le temps requis pour construire des nouveaux cas d’usages : Utiliser des outils modernes et automatiser les processus pour être en mesure d’intégrer rapidement de nouvelles sources de données et créer /modifier des données métiers.
• Les coûts : Évaluer les coûts d'implémentation et d'exploitation des différents outils et services. Cela inclut les frais d'abonnement, les coûts de stockage et les coûts de calcul.
• Les compatibilité avec des compétences existantes (Python, SQL…) : Capitaliser sur les compétences des équipes en place pour leur permettre d’être rapidement opérationnel sur la plateforme.
• La performance : Assurer que la solution choisie peut traiter les volumes de données nécessaires et ainsi répondre aux besoins de performance en termes de latence et de temps de réponse pour obtenir des insights précis.
• L’évolutivité : Avoir le niveau de flexibilité requis pour réaliser des transformations de données complexes.
• La maintenabilité : Privilégier des solutions simples et éprouvées, automatiser au maximum pour faciliter la maintenance.
• L’absence de dépendance à un fournisseur spécifique (No Vendor Lock-in) : Éviter une trop forte dépendance à un outil ou un fournisseur unique en diversifiant les briques technologiques et en s’assurant d’une portabilité entre différents cloud provider.
• Légal : La plateforme doit répondre aux enjeux légaux de traitement de données et engagements contractuels
Et le DataOps dans tout ça ?
Pour répondre à ces contraintes, un socle DataOps solide est essentiel :
Comment construire et déployer de nouveaux cas d’usage ?
- Mettre en place des pipelines de données robustes et automatisés (ETL/ELT).
- Adopter des approches CI/CD pour faciliter l’intégration et le déploiement continu des modèles et transformations de données.
- Standardiser les bonnes pratiques en matière de gouvernance des données.
Comment sécuriser les accès aux données ?
- Implémenter des politiques de gestion des accès (RBAC, ABAC) pour assurer une gestion fine des permissions.
- Chiffrer les données sensibles en transit et au repos.
- Assurer une traçabilité complète des accès et des modifications via des logs et des audits.
Comment garantir la qualité et la fiabilité des données ?
- Mettre en place des tests automatisés pour vérifier l’intégrité des données à chaque étape des pipelines.
- Surveiller la qualité des données (données manquantes, incohérences, anomalies).
- Intégrer des processus de Data Observability pour détecter et résoudre les incidents en temps réel.
Comment assurer la scalabilité et l’optimisation des performances ?
- Définir des architectures modulaires et scalables (Data Lake, Data Mesh, Data Warehouse).
- Optimiser les requêtes et les charges de travail grâce à des solutions de cache, indexation et partitionnement.
- Évaluer régulièrement la charge des ressources pour adapter l’infrastructure et réduire les coûts.
—-
Quelles sont les étapes pour construire sa Modern Data Stack ?
Identifier un cas d’usage
La construction d’une Modern Data Stack doit répondre à un ou plusieurs cas d’usage précis et servir des objectifs, notamment financiers et stratégiques, pour l’entreprise.
Pour la suite de cet article, nous nous placerons dans le cas d’usage suivant :
ex : Une entreprise de vente en ligne souhaite améliorer ses performances marketing. Pour cela, elle a besoin de mieux comprendre le comportement de ses clients afin d’optimiser ses campagnes publicitaires et augmenter ses taux de conversion.
Il s’agit donc ici de construire une architecture efficace permettant de :
- Centraliser les données de différentes sources (CRM, site web, campagnes publicitaires).
- Stocker et transformer les données à des fins analytiques.
- Exposer la donnée aux utilisateurs finaux.
Choisir un datawarehouse
Un datawarehouse comme "Single Source of Truth" (SSOT) centralise toutes les données d’une organisation, assurant que la création de KPIs et l'analytique reposent sur des données uniformes et fiables. Il permet à toutes les équipes d'accéder à une source unique et cohérente, évitant les divergences dans l'utilisation des données.
Le choix du data warehouse influera sur les coûts de stockage et de traitement des données de la Data Platform. Il existe différentes solutions sur le marché, pour la plupart hébergées dans le Cloud et proposant des outils de monitoring des coûts et des performances avancés.
Pour ses faibles coûts de stockage et ses performances, nous choisirons pour cet exemple le data warehouse BigQuery, disponible sur Google Cloud Platform.
Si vous souhaitez en savoir plus sur BigQuery, ses fonctionnalités clés et ses performances, n’hésitez pas à consulter mon article à ce sujet.
Choisir un outil d’ingestion
L’ingestion des données peut représenter un défi délicat dans le cas de certaines data platform, notamment en raison de la multiplicité potentielle des sources de données à agréger.
Pour cette raison, il existe un très large choix d’outils d’ingestion sur le marché. Certains permettent d’ingérer de la donnée en continu, tandis que d’autres ingèrent la donnée par paquets à intervalles réguliers. Certains outils se dédient simplement à déposer la donnée d’un point A à un point B, tandis que d’autres permettent de réaliser des transformations à la volée.
Et même en considérant cette large gamme, certaines entreprises prennent le parti de développer leurs propres outils d’ingestion, afin de corréler les fonctionnalités de l’outil à leur besoin précis.
A cette étape, nous utiliserons Airbyte : sa simplicité d’utilisation en fait un outil idéal pour se connecter à différents outils et logiciels pour centraliser la donnée dans BigQuery. De plus, il est possible d’héberger ses connecteurs Airbyte directement dans le Cloud, sans avoir à maintenir une infrastructure dédiée.
Modéliser et transformer ses données
La modélisation et la transformation des données est généralement effectuée à travers différentes couches du data warehouse. Pour cela, l’utilisation du langage SQL est largement répandue.
DBT est un outil permettant de centraliser et versionner les requêtes de transformation des données du data warehouse. Là-aussi, cet outil offre la possibilité d’un hébergement directement dans le Cloud. Ainsi, les transformations peuvent être régulièrement programmées afin de maintenir une donnée finale à jour sans avoir à maintenir d’infrastructure. Ce choix semble donc idéal pour notre projet.
Exposer et visualiser ses données
Maintenant que les données sont ingérées, stockées et transformées, il manque un dernier outil en bout de chaîne pour les exploiter. Ce type d’outil, appelé outil d’activation (ou d’exposition) de la donnée, peut prendre plusieurs formes :
- Un outil de visualisation de données, sous forme de tableaux et de graphiques
- Des modèles de machine learning
- Un logiciel de type CRM qui utiliserait des données transformées
>, Pour répondre à notre besoin, considérons que l’on souhaite afficher nos données clients sous la forme d’un dashboard d’aide à la décision pour les utilisateurs finaux.
Il serait alors intéressant d’intégrer en bout de chaîne un logiciel comme Looker Studio: simple d’utilisation, il permet facilement de partager des dashboards à différents utilisateurs, tout en gérant les droits d’accès et de modification.
De plus, il s’intègre parfaitement dans l’écosystème Google, dans lequel se trouve déjà nos données stockées.
Architecture dédiée
.png)
A savoir : Nous avons pris dans cet article l'un des chemins possibles pour construire une Modern Data Platform efficace et résiliente.
Nous avons pour cela pris pour point de départ un ou plusieurs des cas d'usages concrets d'une société. En effet, pour remplir correctement son œuvre, une data platform doit avant tout être basée sur un besoin réel. Ce dernier nous a permis, couplé aux autres contraintes structurelles, technologies et budgétaires du client, de faire une sélection adaptée des outils et technologies de notre plate-forme.
--
Vous souhaitez être accompagné par les experts en MDP ?
Contactez-nous via le formulaire de contact ici, un de nos Data Engineers vous contactera rapidement pour discuter de vos problématiques et vous conseillera sur vos pains points.

%20(1).webp)