


Qu'est-ce qu'un data pipeline ?
Un Data Pipeline peut être défini comme un ensemble structuré de processus qui vise à collecter des données depuis une source et à les transporter vers une destination. Les data pipelines sont le cœur des Modern Data Platforms.
Les data pipelines se composent de trois éléments fondamentaux :
- Une ou plusieurs sources fournissant les données collectées. Ces sources peuvent être des bases de données, des API, des fichiers, etc.
- Des étapes de processing pouvant inclure de la transformation de données, du nettoyage et des agrégations pour affiner les données en vue de leur stockage ou de leur analyse.
- Une ou plusieurs destinations des données où les données collectées seront stockées.

Les deux grands types de data pipelines
Il existe deux types de pipelines qui répondent à des besoins de traitement distincts : le traitement par lot et le traitement streaming (flux de données continu).
Le choix du type de data pipeline est essentiel et doit être fait pour chaque cas d'utilisation. Il est important d’éviter la "sur-ingénierie" et de privilégier une approche équilibrée garantissant une efficacité optimale tout en évitant des coûts et une complexité inutile.
Traitement par lots ou batch processing
Les pipelines de traitement par lots sont conçus pour gérer et traiter de grands volumes de données par lots. Ce pipeline consiste en l’exécution régulière de série d’actions contenant des tâches de collecte, de transformation (optionnel) et d’écriture.
Ce type de traitement est utilisé pour la grande majorité des cas d’utilisation, notamment car il est facile à mettre en place et peu coûteux. Il peut par exemple être utilisé pour collecter des données pour du reporting ou des analyses à grand échelle.
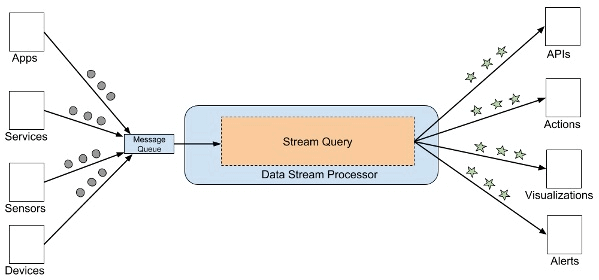
Traitement d'un flux de données continu ou streaming
Un flux de données (ou data stream) est une séquence continue et incrémentale de petits paquets de données qui décrivent généralement une série d'événements dans le temps. Les pipelines de traitement de flux sont conçus pour traiter les données en temps réel, ce qui permet une analyse et une réponse immédiates aux situations changeantes.
Les pipelines de traitement de flux sont utiles pour analyser les données provenant des appareils de l'Internet des objets (IoT), la détection des fraudes, l'analyse des médias sociaux, etc. Ce type de traitement est extrêmement puissant mais peut rapidement devenir complexe et coûteux à maintenir.
Quelle est la différence entre les pipelines de données et les pipelines ETL / ELT ?
Les deux termes sont souvent utilisés comme synonymes, mais un pipeline de données et un pipeline ETL / ELT diffèrent par leur portée et l'ordre des opérations. ETL (Extract, Transform, Load) et ELT (Extract, Load, Transform) correspondent à un sous-ensemble de pipelines de données.
L'ETL consiste à extraire des données d'un système, à les transformer et à les charger dans un autre système. L’ELT quant à lui effectue les mêmes opérations mais dans un ordre différent puisqu’il collecte de la donnée, la charge en base, dans un datawarehouse ou un datalake, puis la transforme, une fois qu’elle est stockée.
Les data pipelines peuvent être des pipelines ETL ou ELT mais ne contiennent pas forcément d’étape de transformation par exemple. De plus, les processus ETL et ELT sont très souvent du batch processing alors qu’un data pipeline peut également être du streaming.
Quels sont les outils et technologies clés pour construire des data pipelines
Il existe énormément d’outils permettant de créer des pipelines de données. Les pipelines étant composés de plusieurs éléments (source, destination, traitements), il est possible de créer une multitude de combinaisons de solutions de la Modern Data Stack pour répondre à un même besoin.
Selon les sources, pour collecter de la donnée, il est possible d’utiliser des scripts Python orchestrés avec Apache Airflow ou Dagster ou des outils d’ingestion comme Airbyte ou Fivetran. La transformation des données peut se faire avec des scripts SQL, des scripts Python ou des outils comme dbt et Matillon. Il existe également des outils ETL complets tels que Azure Data Factory, Airbyte et AWS Data Pipeline. Pour faire du streaming, des solutions courantes sont Apache Kafka, Google Pub/Sub et AWS Kinesis.
Cas d'utilisation de data pipelines
Imaginons un cas d’usage très simple avec une entreprise possédant une plateforme de vente de produits alimentaires en ligne et souhaitant suivre plus précisément quelques chiffres clés sur les commandes passées sur sa plateforme.
La mise en place d’un data pipeline pourrait être un excellent moyen de collecter les données de son site pour alimenter des tableaux de bord de reporting.
Les dashboards n’ayant pas besoin d’être mis à jour en temps réel, l’utilisation d’un pipeline en batch semble pertinent. Il est alors envisageable de créer un flux collectant toutes les nuits les données des commandes passées la veille, les chargeant dans une base puis transformant et agrégeant ces données afin de calculer les indicateurs désirés.
Imaginons maintenant que cette entreprise souhaite aller plus loin et automatiser le déclenchement de notifications envoyées à l’acheteur pour l’avertir du changement de statut de sa commande.
Cette solution peut également être faite en batch processing mais le streaming pourrait être un moyen efficace de tenir au courant en temps réel l’acheteur.
Pour cela, l’entreprise pourrait alors mettre en place un service de streaming pour constamment être à l’écoute des changements de statuts indiqués par le site et déclencher des actions dès qu’un changement est détecté.
Chez Modeo, nous aidons nos clients à construire des pipelines de données efficaces qui s'intègrent à leurs systèmes existants et répondent à leurs besoins en matière de traitement de données.
Contactez-nous pour une consultation personnalisée et découvrez ce que nous pouvons faire pour votre entreprise !

%20(1).webp)